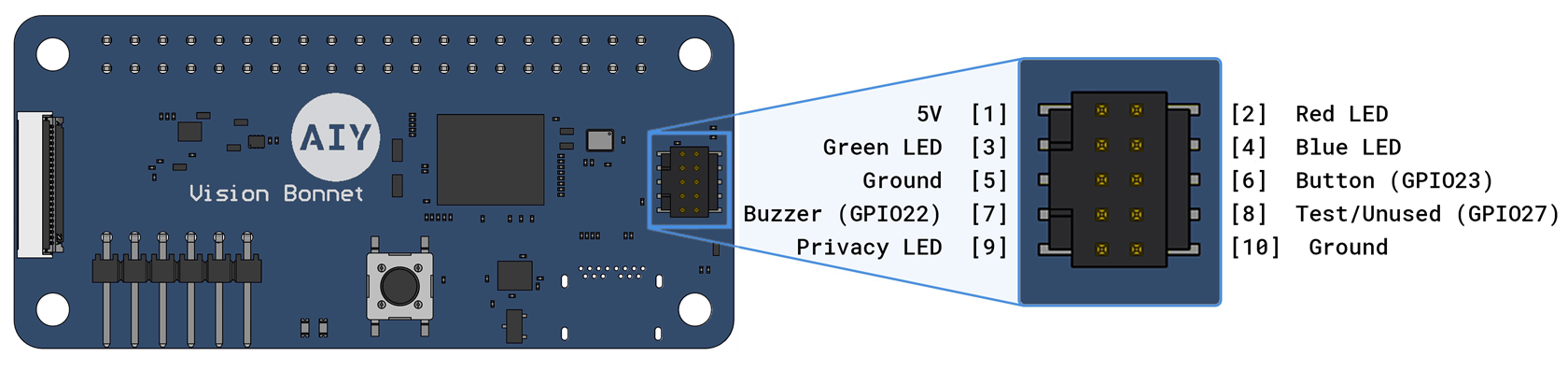
The Vision Bonnet also includes a dedicated microcontroller (MCU) that enables the following additional features:
- Control of four additional GPIO pins, freeing up the Pi GPIOs for other uses
- PWM support for servo/motor control without taxing the Raspberry Pi's CPU
- Analog input support for all GPIO pins via on-board analog-to-digital converter (ADC)
- Control of the two LEDs on the bonnet
The extra GPIO pins are provided on the top of the Vision Bonnet (see figure 2). You can control the GPIOs and LEDs with the gpiozero library, using pin names PIN_A, PIN_B, PIN_C, PIN_D, LED_1, and LED_2.
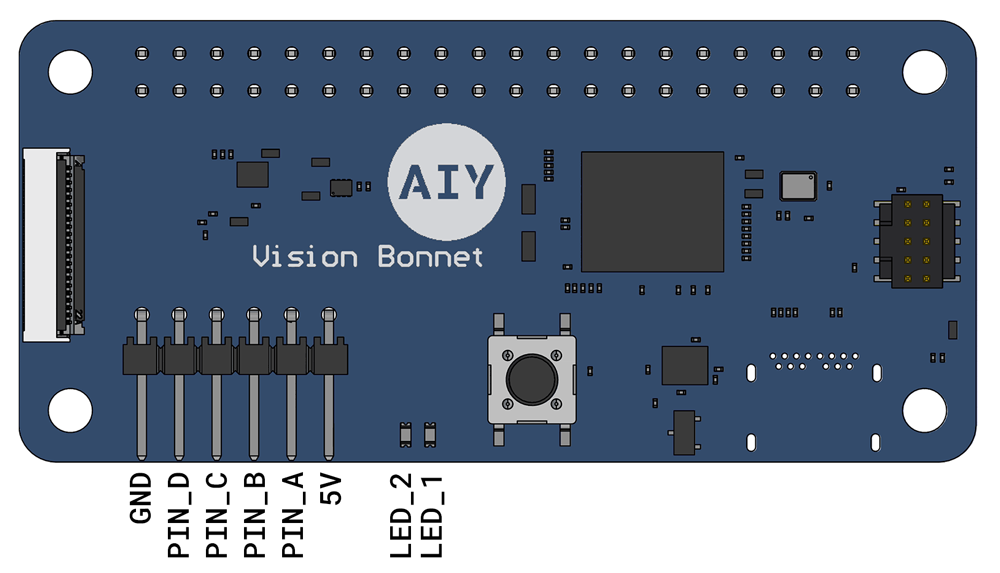
Figure 2. GPIO expansion pins on the Vision Bonnet
The gpiozero-compatible pin definitions are provided by the aiy.pins package. You can use these definitions to construct standard gpiozero devices like LEDs, Servos, and Buttons.
If you want to dig deeper into these pins, checkout the MCU (SAM D09) docs—the bonnet GPIO pin names correspond to the
MCU pins as follows:
- PIN_A = PA04
- PIN_B = PA05
- PIN_C = PA10
- PIN_D = PA11
Also see how to read the analog voltages.
WARNING: Before you connect any wires to the Vision Bonnet, be sure your Raspberry Pi is disconnected from any power source. Failure to do so could result in electric shock, serious injury, death, fire or damage to your board or connected components and equipment.
LED example
Note: The following example code might not be installed on your SD card right out of the box. Be sure that you are running the latest system image.
Although the LEDs on the bonnet are easy to use, you probably want your light to appear somewhere else. So connect an LED to PIN_A and GND as shown in figure 3. (Be sure the long/bent leg of the LED is connected to PIN_A; the resistor can be any size over 50 ohms.)
Then run the led_chaser.py example code:
cd ~/AIY-projects-python/src/examples/gpiozero
./led_chaser.py
It takes several seconds for the script to begin. Once it does, your light will blink on and off. To stop, press Control+C.
If the light does not blink, continue to wait another 15 seconds. If it still does not blink, look for any errors in the terminal window. Then press Control+C to stop the script, power off the kit, and double check all wiring. Then try again.
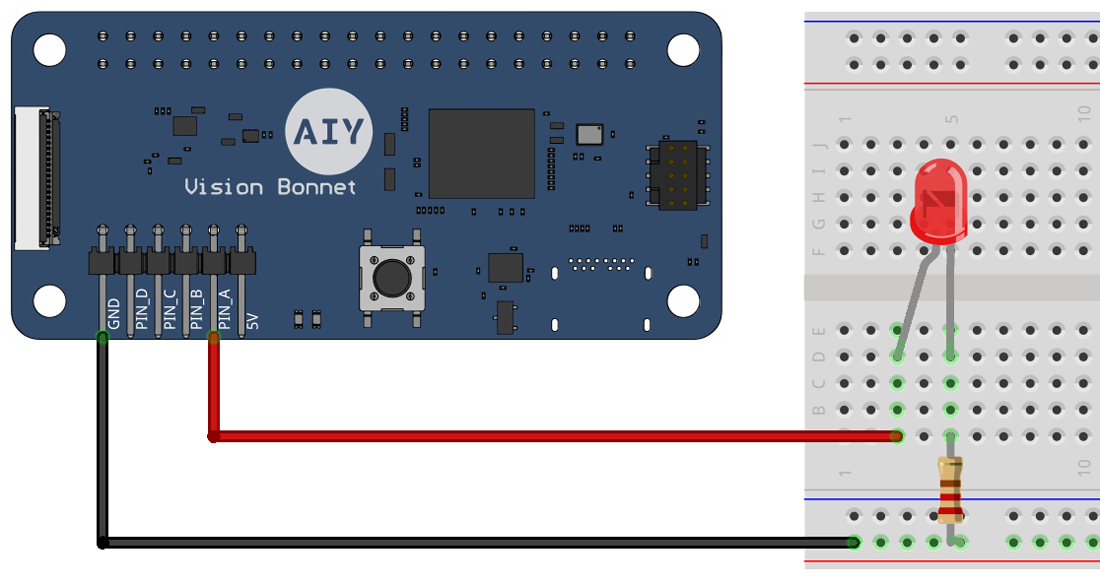
Figure 3. An LED connected to the Vision Bonnet
The led_chaser.py script is designed to light up 4 LEDs in sequence, as shown here:
from time import sleep
from gpiozero import LED
from aiy.pins import (PIN_A, PIN_B, PIN_C, PIN_D)
leds = (LED(PIN_A), LED(PIN_B), LED(PIN_C), LED(PIN_D))
while True:
for led in leds:
led.on()
sleep(0.5)
led.off()
Of course, the code works fine with just one LED connected. But once you have the one LED working, try connecting LEDs to PIN_B, PIN_C, and PIN_D in the same way, and run the code again.
Servo example
Because the GPIO pins on the Vision Bonnet are controlled by an on-board MCU, they perform pulse-width modulation (PWM) more precisely than the Raspberry Pi. So these pins are great for controlling servos.
To try it out, connect a servo to the GND, PIN_B, and 5V pins as shown in figure 4, and then run the servo_example.py script:
cd ~/AIY-projects-python/src/examples/gpiozero
./servo_example.py
It takes several seconds for the script to begin. Once it does, your servo should rotate back and forth between the minimum, maximum, and neutral position. But each servo can be a little different, so you might need to tune the parameters of the code to achieve a perfect alignment with your servo's full range of motion.
If the servo does not respond, continue to wait another 15 seconds. If it still does nothing, look for any errors in the terminal window. Then press Control+C to stop the script, power off the kit, and double check all wiring. Then try again.
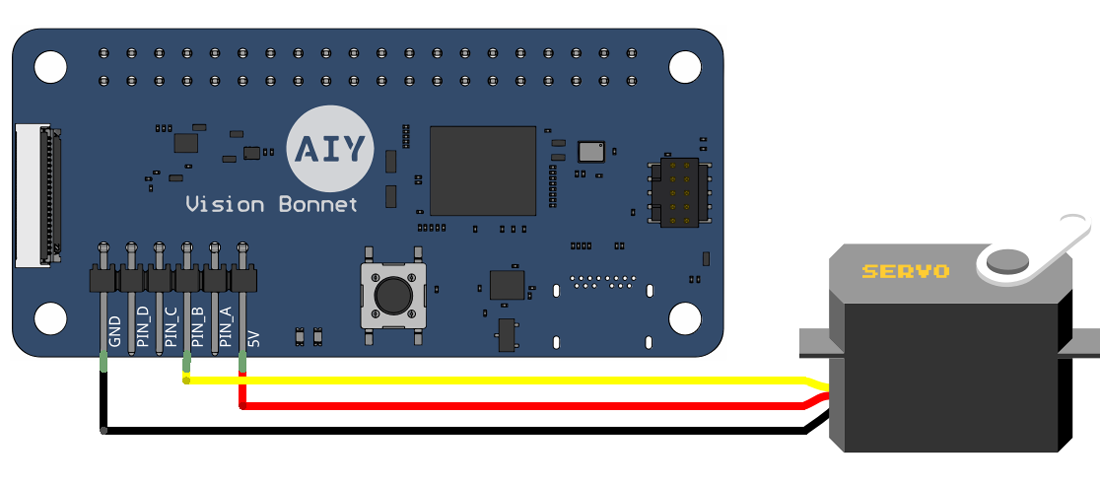
Figure 4. A servo connected to the Vision Bonnet
The servo_example.py script uses the gpiozero Servo object to control the servo. The important parts of the script look like this:
from gpiozero import Servo
from aiy.pins import PIN_B
# Create a servo with the custom values to give the full dynamic range.
tuned_servo = Servo(PIN_B, min_pulse_width=.0005, max_pulse_width=.0019)
# Move the Servos back and forth until the user terminates the example.
while True:
tuned_servo.max()
sleep(1)
tuned_servo.mid()
sleep(1)
tuned_servo.min()
sleep(1)
To adjust the rotation range of your servo, open the Python script and adjust the parameters of the Servo() constructor. Also see the Servo API documentation.
For more examples using the GPIO pins, see
the AIY GitHub examples.
All of these example files are already available on your Vision Kit in the direcory ~/AIY-projects-python/src/examples/. Just be sure you have the latest system image on your SD card.